Spark开发文档
Apache Spark 是一个开源的大数据处理框架,旨在快速处理大规模数据集。它提供了分布式计算能力,支持批处理和流处理。Spark 提供了丰富的API,支持多种编程语言(如Java、Scala、Python、R),并且能在不同的集群管理器(如Hadoop YARN、Kubernetes)上运行。Spark 通过内存计算和高度优化的执行引擎,显著提高了数据处理速度,广泛应用于数据分析、机器学习和图计算等领域。
基础配置
创建项目
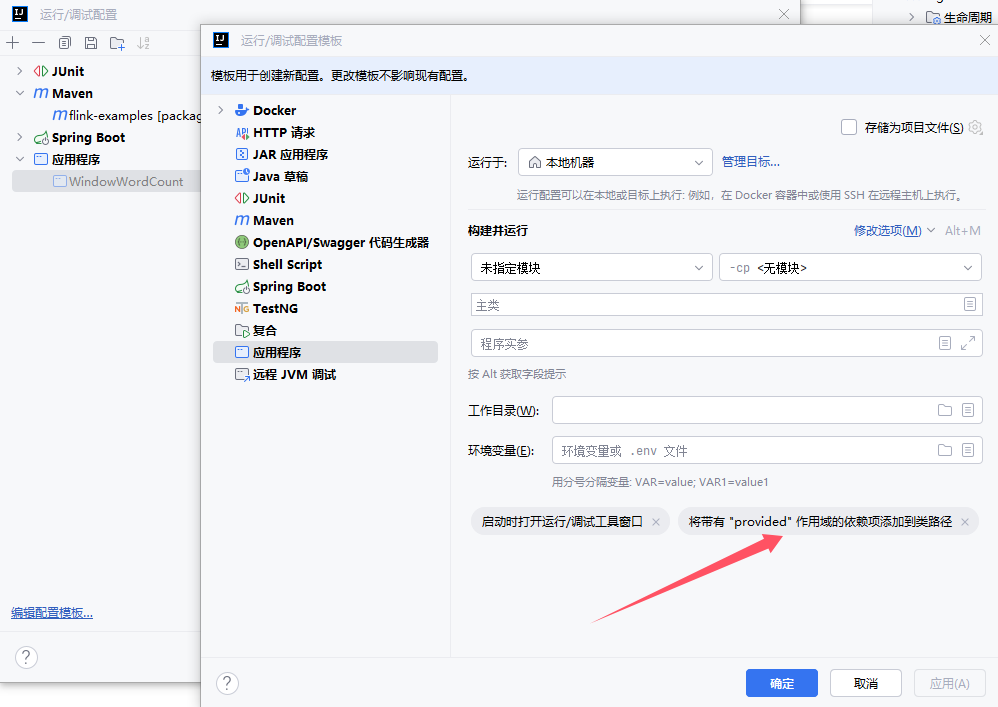
创建Maven项目,IDEA配置该项目SDK为JDK8、Maven的JRE也配置文JDK8、应用程序配置需要设置 provided 作用域
配置pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- 项目模型版本 -->
<modelVersion>4.0.0</modelVersion>
<!-- 项目坐标 -->
<groupId>local.ateng.java.spark</groupId>
<artifactId>spark-examples</artifactId>
<version>v1.0</version>
<name>spark-examples</name>
<description>
Maven项目使用Java8对的Spark使用
</description>
<!-- 项目属性 -->
<properties>
<!-- 默认主程序 -->
<start-class>local.ateng.java.spark.Main</start-class>
<java.version>8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven-compiler.version>3.12.1</maven-compiler.version>
<maven-shade.version>3.5.1</maven-shade.version>
<lombok.version>1.18.36</lombok.version>
<fastjson2.version>2.0.53</fastjson2.version>
<hutool.version>5.8.35</hutool.version>
<spark.version>3.5.4</spark.version>
<hadoop.version>3.3.6</hadoop.version>
</properties>
<!-- 项目依赖 -->
<dependencies>
<!-- Hutool: Java工具库,提供了许多实用的工具方法 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<!-- Lombok: 简化Java代码编写的依赖项 -->
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- 高性能的JSON库 -->
<!-- https://github.com/alibaba/fastjson2/wiki/fastjson2_intro_cn#0-fastjson-20%E4%BB%8B%E7%BB%8D -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<!-- SLF4J API -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
<scope>provided</scope>
</dependency>
<!-- Log4j 2.x API -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.19.0</version>
<scope>provided</scope>
</dependency>
<!-- Log4j 2.x 实现 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.19.0</version>
<scope>provided</scope>
</dependency>
<!-- SLF4J 和 Log4j 2.x 绑定 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.19.0</version>
<scope>provided</scope>
</dependency>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<!-- 插件仓库配置 -->
<repositories>
<!-- Central Repository -->
<repository>
<id>central</id>
<name>阿里云中央仓库</name>
<url>https://maven.aliyun.com/repository/central</url>
<!--<name>Maven官方中央仓库</name>
<url>https://repo.maven.apache.org/maven2/</url>-->
</repository>
</repositories>
<!-- 构建配置 -->
<build>
<finalName>${project.name}-${project.version}</finalName>
<plugins>
<!-- Maven 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven-compiler.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
<!-- Maven Shade 打包插件 -->
<!-- https://maven.apache.org/plugins/maven-shade-plugin/shade-mojo.html -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>${maven-shade.version}</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<!-- 禁用生成 dependency-reduced-pom.xml 文件 -->
<createDependencyReducedPom>false</createDependencyReducedPom>
<!-- 附加shaded工件时使用的分类器的名称 -->
<shadedClassifierName>shaded</shadedClassifierName>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>${start-class}</mainClass> <!-- 指定默认主程序 -->
</transformer>
</transformers>
<artifactSet>
<!-- 排除依赖项 -->
<excludes>
<exclude>org.apache.logging.log4j:*</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>ch.qos.logback:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- 不复制 META-INF 下的签名文件 -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.MF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
<exclude>META-INF/services/java.sql.Driver</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>配置log4j2.properties
在resources目录下创建log4j2的日志配置文件
# 配置日志格式
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{ISO8601} [%t] %-5level %logger{36} - %msg%n
# 定义根日志级别
rootLogger.level = INFO
rootLogger.appenderRefs = console
rootLogger.appenderRef.console.ref = ConsoleAppender
# Spark
logger.spark.name = org.apache.spark
logger.spark.level = WARN
logger.spark.appenderRefs = console
logger.spark.appenderRef.console.ref = ConsoleAppender
logger.sparkproject.name = org.sparkproject
logger.sparkproject.level = WARN
logger.sparkproject.appenderRefs = console
logger.sparkproject.appenderRef.console.ref = ConsoleAppender
# Hadoop
logger.flink.name = org.apache.hadoop
logger.flink.level = WARN
logger.flink.appenderRefs = console
logger.flink.appenderRef.console.ref = ConsoleAppender使用WordCount
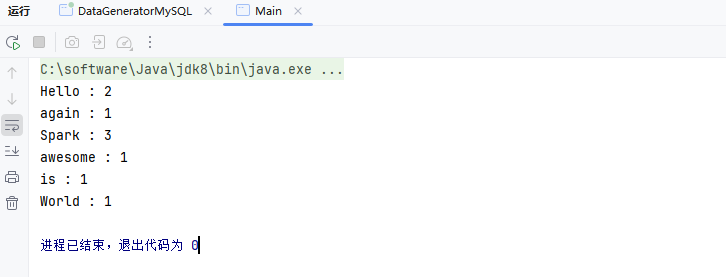
创建第一个Spark程序WordCount
package local.ateng.java.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("RDD Example");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 自定义一组数据
String[] data = {
"Hello Spark World",
"Spark is awesome",
"Hello again Spark"
};
// 将数据并行化为RDD
JavaRDD<String> inputData = sc.parallelize(Arrays.asList(data));
// 1. 将每行数据拆分为单词
JavaRDD<String> words = inputData.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
// 2. 转换为键值对 (word, 1)
JavaPairRDD<String, Integer> wordPairs = words.mapToPair(word -> new Tuple2<>(word, 1));
// 3. 按键聚合,计算每个单词的出现次数
JavaPairRDD<String, Integer> wordCounts = wordPairs.reduceByKey(Integer::sum);
// 4. 打印结果
wordCounts.collect().forEach(result -> {
System.out.println(result._1 + " : " + result._2);
});
// 停止Spark上下文
sc.stop();
}
}
RDD
RDD(Resilient Distributed Dataset 弹性分布式数据集)是 Spark 的核心抽象,表示不可变的分布式数据集合,支持惰性求值、分区存储和容错性。通过转换(如 map、filter)生成新 RDD,通过动作(如 collect、count)触发计算。RDD 可从集合、文件等创建,适合灵活数据处理,但性能不如 DataFrame 和 Dataset,高级开发中使用逐渐减少,但理解其概念有助于掌握 Spark 内部机制。
数据源
本地文件
package local.ateng.java.spark.rdd.read;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取本地文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class ReadLocalFile {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取本地文件");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("file:///D:/Temp/2025/202501/20250121/my_user.csv");
// 输出文件内容
textFileRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}HDFS文件
配置HDFS
Windows操作系统配置Hadoop
- 参考:地址
操作系统设置环境变量
HADOOP_GROUP_NAME=ateng
HADOOP_USER_NAME=admin创建目录并设置权限
hadoop fs -mkdir -p /data
hadoop fs -chown admin:ateng /data添加依赖
<!-- Hadoop HDFS客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-reload4j</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<artifactId>gson</artifactId>
<groupId>com.google.code.gson</groupId>
</exclusion>
</exclusions>
</dependency>代码如下
package local.ateng.java.spark.rdd.read;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class ReadHDFSFile {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 输出文件内容
textFileRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}递归读取HDFS文件
Spark 支持递归读取子目录中的所有文件。
package local.ateng.java.spark.rdd.read;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 递归读取HDFS文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class ReadHDFSRecursiveFile {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件");
// 启用递归读取
conf.set("spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive", "true");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/flink/sink");
// 输出文件内容
long count = textFileRDD.count();
System.out.println(count);
//textFileRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}算子
参考:官方文档
Filter
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件并过滤内容
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorFilter {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件并过滤内容");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用filter操作,筛选出满足特定条件的数据。例如,只保留包含特定关键词的行。
JavaRDD<String> filteredRDD = textFileRDD.filter(line -> line.contains("重庆"));
// 输出文件内容
filteredRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}Map
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件并数据转换
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorMap {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件并数据转换");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用map操作,对每一行数据进行转换,创建新的RDD。例如,将每一行数据按逗号分割并获取特定列的值。
JavaRDD<String> transformedRDD = textFileRDD.map(line -> line.split(",")[1]);
// 输出文件内容
transformedRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}MapEntity
转换成实体类
创建实体类
package local.ateng.java.spark.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.Date;
/**
* 用户实体类
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class MyUser implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 用户ID
*/
private Long id;
/**
* 用户姓名
*/
private String name;
/**
* 用户年龄
* 注意:这里使用Integer类型,表示年龄是一个整数值。
*/
private Integer age;
/**
* 分数
*/
private BigDecimal score;
/**
* 用户生日
* 注意:这里使用Date类型,表示用户的生日。
*/
private LocalDate birthday;
/**
* 用户所在省份
*/
private String province;
/**
* 用户所在城市
*/
private String city;
/**
* 创建时间
*/
private LocalDateTime createTime;
}创建MapEntity代码
package local.ateng.java.spark.rdd.operator;
import cn.hutool.core.date.LocalDateTimeUtil;
import local.ateng.java.spark.entity.MyUser;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.math.BigDecimal;
import java.time.LocalDate;
/**
* 读取HDFS文件并数据转换
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorMapEntity {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件并数据转换");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用map操作,对每一行数据进行转换,创建新的RDD。例如,将每一行数据按逗号分割并获取特定列的值。
JavaRDD<MyUser> myUserRDD = textFileRDD
.filter(line -> !"id,name,age,score,birthday,province,city,create_time".equals(line))
.map(line -> {
String[] split = line.split(",");
return MyUser.builder()
.id(Long.parseLong(split[0]))
.name(split[1])
.age(Integer.parseInt(split[2]))
.score(new BigDecimal(split[3]))
.birthday(LocalDateTimeUtil.parseDate(split[4], "yyyy-MM-dd"))
.province(split[5])
.city(split[6])
.createTime(LocalDateTimeUtil.parse(split[7], "yyyy-MM-dd HH:mm:ss.SSS"))
.build();
});
// 输出文件内容
myUserRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}FlatMap
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
/**
* 读取HDFS文件并数据转换
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorFlatMap {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件并数据转换");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用map操作,对每一行数据进行转换,创建新的RDD。例如,将每一行数据按逗号分割并获取特定列的值。
JavaRDD<String> flatMapRDD = textFileRDD.flatMap(line -> {
String[] fields = line.split(",");
return Arrays.asList(fields[1] + "-" + fields[5]).iterator();
});
// 输出文件内容
flatMapRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}Checkpoint&cache
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件,缓存数据和数据检查点
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorCheckpoint {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,缓存数据和数据检查点");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用cache或persist操作,将 textFileRDD 缓存到内存中,确保 Spark 在后续操作中不会重新计算该 RDD,而是直接从缓存中读取。
textFileRDD.cache(); // 或 textFileRDD.persist(StorageLevel.MEMORY_ONLY());
// 数据检查点:针对 textFileRDD 做检查点计算
sc.setCheckpointDir("hdfs://server01:8020/spark/checkpoint");
textFileRDD.checkpoint();
// 输出文件内容
textFileRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}Count
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件并计算行数
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorCount {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件并计算行数");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用count操作,获取RDD中行数。
long count = textFileRDD.count();
// 打印结果
System.out.println("Total lines: " + count);
// 关闭Spark上下文
sc.close();
}
}SaveAsTextFile
package local.ateng.java.spark.rdd.operator;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件,保存结果数据到HDFS
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorSaveTo {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,保存结果数据到HDFS");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 使用filter操作,筛选出满足特定条件的数据。例如,只保留包含特定关键词的行。
JavaRDD<String> filteredRDD = textFileRDD.filter(line -> line.contains("重庆"));
// 使用saveAsTextFile方法,将RDD保存到文本文件或其他输出格式中。
filteredRDD.saveAsTextFile("hdfs://server01:8020/data/output/my_user_cq");
// 关闭Spark上下文
sc.close();
}
}Union
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 读取HDFS文件,合并数据
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorUnion {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,合并数据");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
textFileRDD.cache();
// 使用filter操作,筛选出满足特定条件的数据。例如,只保留包含特定关键词的行。
JavaRDD<String> filtered1RDD = textFileRDD.filter(line -> line.contains("重庆"));
JavaRDD<String> filtered2RDD = textFileRDD.filter(line -> line.contains("成都"));
// 使用union操作,将两个RDD合并为一个。
JavaRDD<String> combinedRDD = filtered1RDD.union(filtered2RDD);
// 打印RDD中的内容
combinedRDD.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}GroupBy
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
/**
* 读取HDFS文件,分组聚合
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorGroupBy {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,分组聚合");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 分组聚合
JavaPairRDD<String, Long> rdd = textFileRDD
.groupBy(line -> line.split(",")[5])
.mapValues(value -> value.spliterator().estimateSize());
// 输出文件内容
rdd.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}ReduceByKey
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
/**
* 读取HDFS文件,分组操作
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorReduceByKey {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,分组操作");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 聚合
JavaPairRDD<String, Long> rdd = textFileRDD
.mapToPair(line -> {
String[] fields = line.split(",");
return new Tuple2<>(fields[5], 1L);
})
.reduceByKey((line1, line2) -> line1 + line2);
// 输出文件内容
rdd.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}CombineByKey
package local.ateng.java.spark.rdd.operator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import scala.Tuple2;
/**
* 读取HDFS文件,复杂聚合
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class OperatorCombineByKey {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
conf.setAppName("读取HDFS文件,复杂聚合");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建Spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 将数据并行化为RDD
JavaRDD<String> textFileRDD = sc.textFile("hdfs://server01:8020/data/my_user.csv");
// 复杂聚合
JavaPairRDD<String, Long> rdd = textFileRDD
.mapToPair(line -> {
String[] fields = line.split(",");
return new Tuple2<>(fields[5], 1L);
})
.combineByKey(
// createCombiner: 初始化累加器 (score, 1)
count -> new Tuple2<>(count, 1),
// mergeValue: 合并新值到当前累加器 (累加分数, 累加数量)
(acc, count) -> new Tuple2<>(acc._1 + count, acc._2 + 1),
// mergeCombiners: 合并分区的累加器
(acc1, acc2) -> new Tuple2<>(acc1._1 + acc2._1, acc1._2 + acc2._2)
).mapValues(value -> value._1 + value._2);
// 输出文件内容
rdd.foreach(line -> System.out.println(line));
// 关闭Spark上下文
sc.close();
}
}SQL
Spark SQL 的一种用途是执行 SQL 查询。 Spark SQL 还可用于从现有 Hive 安装读取数据。有关如何配置此功能的更多信息,请参阅Hive 表部分。当从另一种编程语言中运行 SQL 时,结果将作为Dataset/DataFrame返回。您还可以使用命令行 或通过JDBC/ODBC与 SQL 接口进行交互。
基础配置
数据准备
连接Hive
beeline -u jdbc:hive2://server01:10000 -n admin连接Hive创建表并写入数据
CREATE EXTERNAL TABLE my_user (
id BIGINT,
name STRING,
age INT,
score DOUBLE,
birthday TIMESTAMP,
province STRING,
city STRING,
createTime TIMESTAMP
)
STORED AS PARQUET
LOCATION '/hive/warehouse/my_user_hive';查看表结构
DESCRIBE EXTENDED my_user;写入数据
通过flink-examples模块中的FlinkSQL生成模拟数据写入Hive表中
local.ateng.java.SQL.SourceAndSink.Hive查看数据
SELECT * FROM my_user LIMIT 10;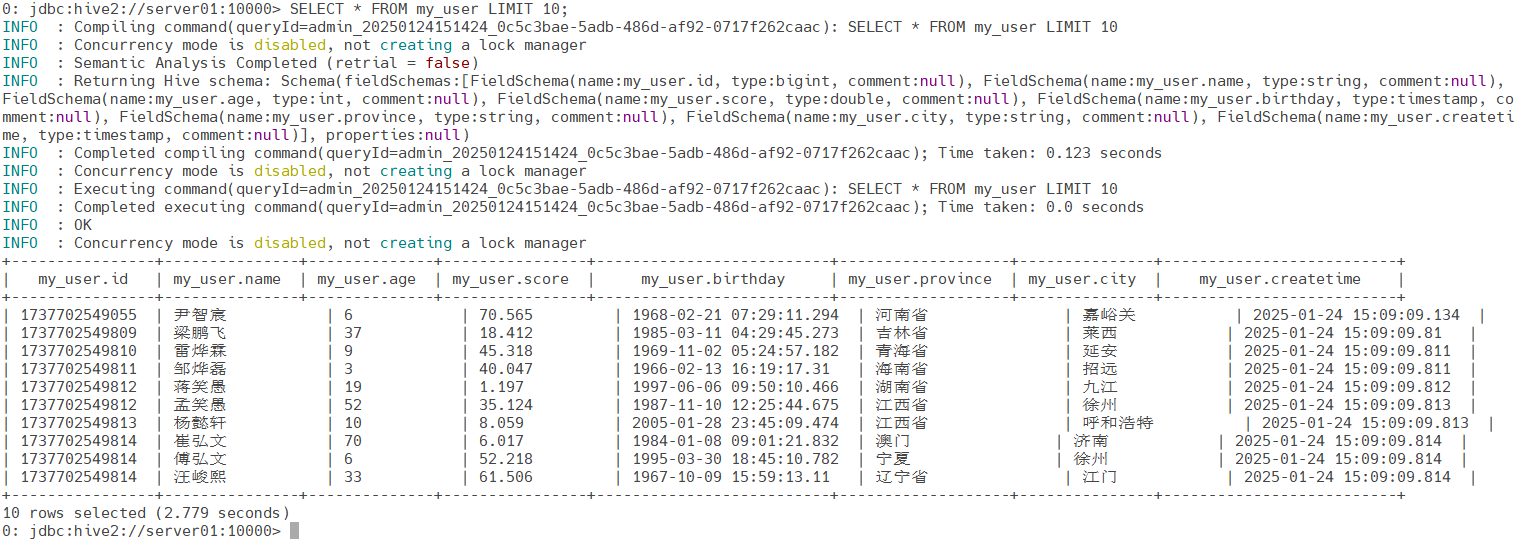
添加依赖
<!-- Spark SQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- Spark Hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>添加配置文件
将集群的hive-site.xml拷贝在resources目录下
查看表
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;
/**
* 第一个SparkSQL代码,查看表
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
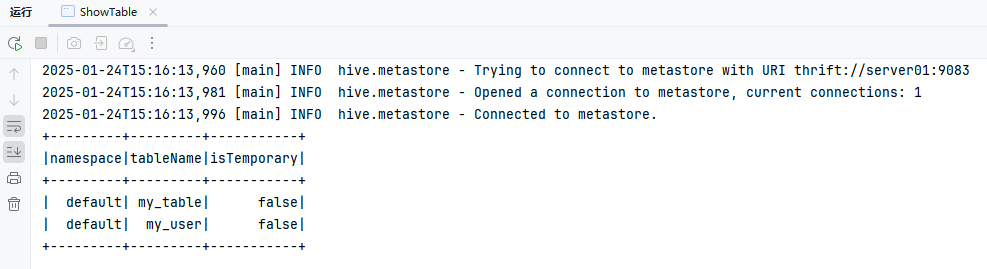
public class ShowTable {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查看表");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 显示Hive表
spark.sql("SHOW TABLES").show();
// 停止SparkSession,释放资源
spark.stop();
}
}
使用SQL
查询数量
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 查询数据数量
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
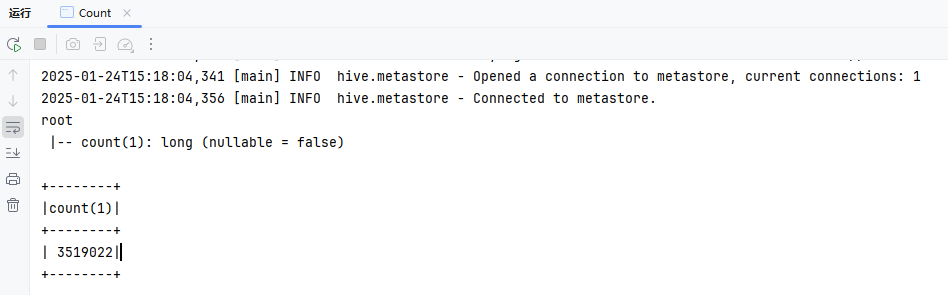
public class Count {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
Dataset<Row> ds = spark.sql("SELECT COUNT(*) FROM my_user");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
SQL填充
package local.ateng.java.spark.sql;
import cn.hutool.core.util.StrUtil;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* SQL填充
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
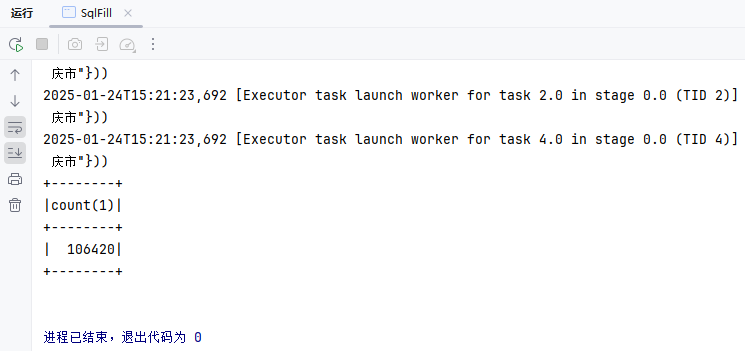
public class SqlFill {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT COUNT(*) FROM my_user WHERE province = '{}'";
Dataset<Row> ds = spark.sql(StrUtil.format(sql,"重庆市"));
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
分组聚合
SQL
select province,
sum(score) as score_sum,
count(id) as id_count
from my_user
where birthday between '1990-01-01' and '2000-01-01'
group by province
having sum(score) > 1000
order by score_sum desc;代码
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 查询数据数量
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class GroupBy {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
Dataset<Row> ds = spark.sql("select province,\n" +
" sum(score) as score_sum,\n" +
" count(id) as id_count\n" +
"from my_user\n" +
"where birthday between '1990-01-01' and '2000-01-01'\n" +
"group by province\n" +
"having sum(score) > 1000\n" +
"order by score_sum desc;");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}窗口函数分析
SQL
SELECT province, id, name, age, score, birthday, city
FROM (
SELECT province, id, name, age, score, birthday, city,
RANK() OVER (PARTITION BY province ORDER BY score DESC) AS rank
FROM my_user
) ranked_data
WHERE rank <= 5
ORDER BY province, rank;代码
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 窗口函数分析
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
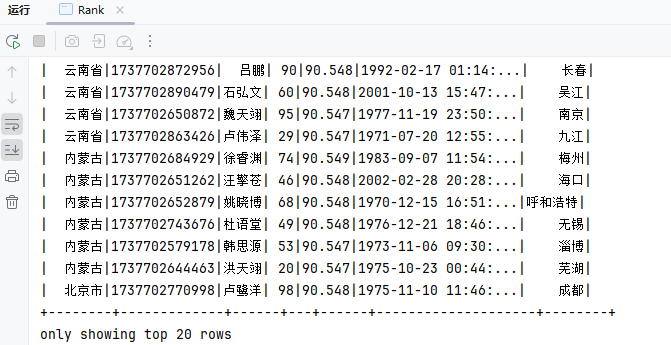
public class Rank {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("窗口函数分析");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
Dataset<Row> ds = spark.sql("SELECT province, id, name, age, score, birthday, city\n" +
"FROM (\n" +
" SELECT province, id, name, age, score, birthday, city,\n" +
" RANK() OVER (PARTITION BY province ORDER BY score DESC) AS rank\n" +
" FROM my_user\n" +
") ranked_data\n" +
"WHERE rank <= 5\n" +
"ORDER BY province, rank;");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
时间序列分析
SQL
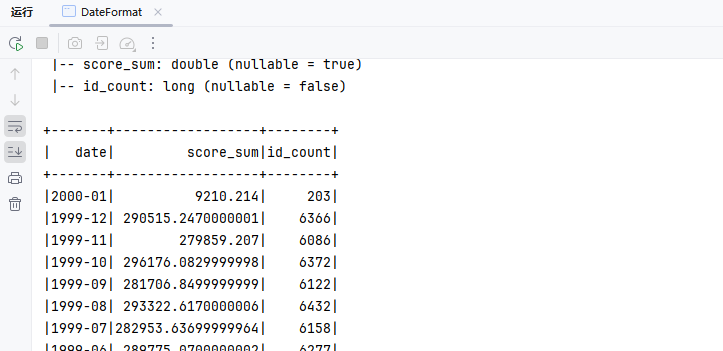
SELECT date_format(TO_DATE(birthday), 'yyyy-MM') AS date,
SUM(score) AS score_sum,
COUNT(id) AS id_count
FROM my_user
WHERE TO_DATE(birthday) BETWEEN '1990-01-01' AND '2000-01-01'
GROUP BY date_format(TO_DATE(birthday), 'yyyy-MM')
ORDER BY date DESC;代码
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 时间序列分析
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class DateFormat {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("时间序列分析");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
Dataset<Row> ds = spark.sql("SELECT date_format(TO_DATE(birthday), 'yyyy-MM') AS date,\n" +
" SUM(score) AS score_sum,\n" +
" COUNT(id) AS id_count\n" +
"FROM my_user\n" +
"WHERE TO_DATE(birthday) BETWEEN '1990-01-01' AND '2000-01-01'\n" +
"GROUP BY date_format(TO_DATE(birthday), 'yyyy-MM')\n" +
"ORDER BY date DESC;");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
子查询优化
SQL
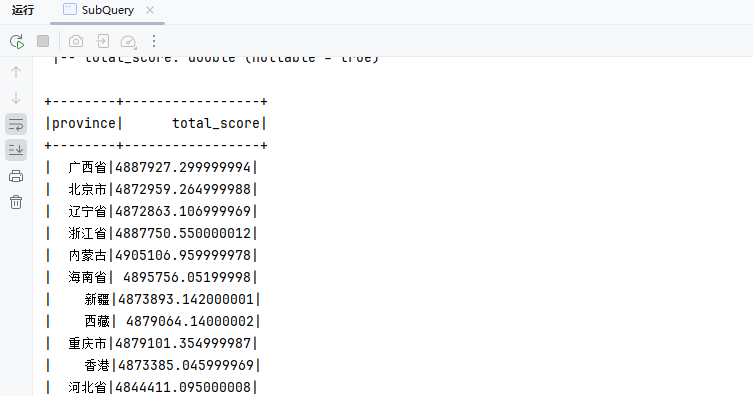
WITH user_totals AS (
SELECT province, SUM(score) AS total_score
FROM my_user
GROUP BY province
)
SELECT *
FROM user_totals
WHERE total_score > 10000;代码
package local.ateng.java.spark.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 子查询优化
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class SubQuery {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("时间序列分析");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
Dataset<Row> ds = spark.sql("WITH user_totals AS (\n" +
" SELECT province, SUM(score) AS total_score\n" +
" FROM my_user\n" +
" GROUP BY province\n" +
")\n" +
"SELECT *\n" +
"FROM user_totals\n" +
"WHERE total_score > 10000;");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
用户自定义函数(UDF)
计算某一列的数据长度
UDF
package local.ateng.java.spark.sql.udf;
import org.apache.spark.sql.api.java.UDF1;
/**
* 数据长度
* 一元UDF
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class StringLengthUDF implements UDF1<String, Integer> {
@Override
public Integer call(String input) throws Exception {
return input == null ? 0 : input.length();
}
}使用函数
package local.ateng.java.spark.sql.udf;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
/**
* 用户自定义函数:计算某一列的数据长度
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class StringLengthSQL {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 注册 UDF
spark.udf().register("stringLengthUDF", new StringLengthUDF(), DataTypes.IntegerType);
// 执行SQL查询
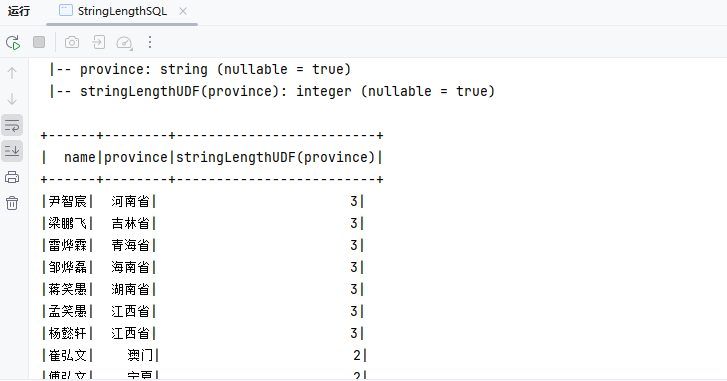
Dataset<Row> ds = spark.sql("SELECT name,province,stringLengthUDF(province) FROM my_user LIMIT 10");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
转换某一列为大写
UDF
package local.ateng.java.spark.sql.udf;
import org.apache.spark.sql.api.java.UDF1;
/**
* 小写转大写
* 一元UDF
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class UpperCaseUDF implements UDF1<String, String> {
@Override
public String call(String input) throws Exception {
return input == null ? "" : input.toUpperCase();
}
}使用函数
package local.ateng.java.spark.sql.udf;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
/**
* 用户自定义函数:转换某一列为大写
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class UpperCaseSQL {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 注册 UDF
spark.udf().register("upperCaseUDF", new UpperCaseUDF(), DataTypes.StringType);
// 执行SQL查询
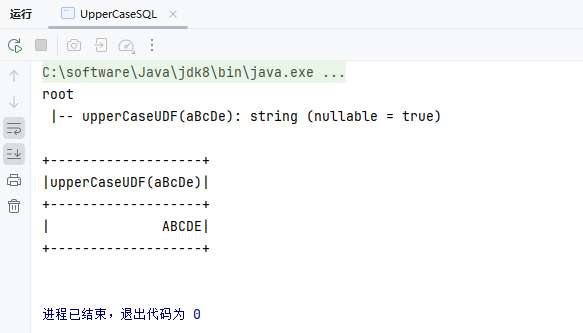
Dataset<Row> ds = spark.sql("SELECT upperCaseUDF('aBcDe')");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
计算两列数据的和
UDF
package local.ateng.java.spark.sql.udf;
import org.apache.spark.sql.api.java.UDF2;
/**
* 两列数据的和
* 二元UDF
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class SumUDF implements UDF2<Integer, Integer, Integer> {
@Override
public Integer call(Integer t1, Integer t2) throws Exception {
return t1 + t2;
}
}使用函数
package local.ateng.java.spark.sql.udf;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
/**
* 用户自定义函数:计算两列数据的和
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
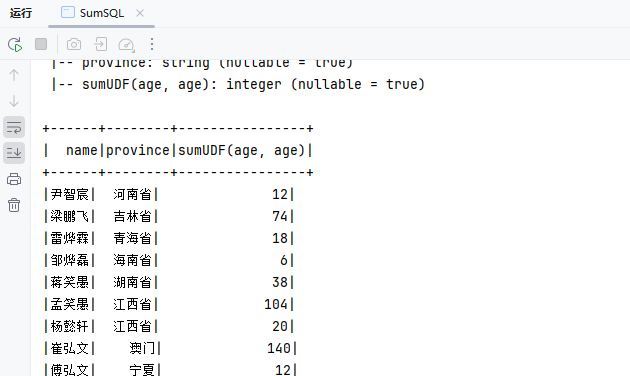
public class SumSQL {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("查询数据数量");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 注册 UDF
spark.udf().register("sumUDF", new SumUDF(), DataTypes.IntegerType);
// 执行SQL查询
Dataset<Row> ds = spark.sql("SELECT name,province,sumUDF(age,age) FROM my_user LIMIT 10");
// 显示 DataFrame 的结构
ds.printSchema();
// 显示查询结果
ds.show();
// 停止SparkSession,释放资源
spark.stop();
}
}
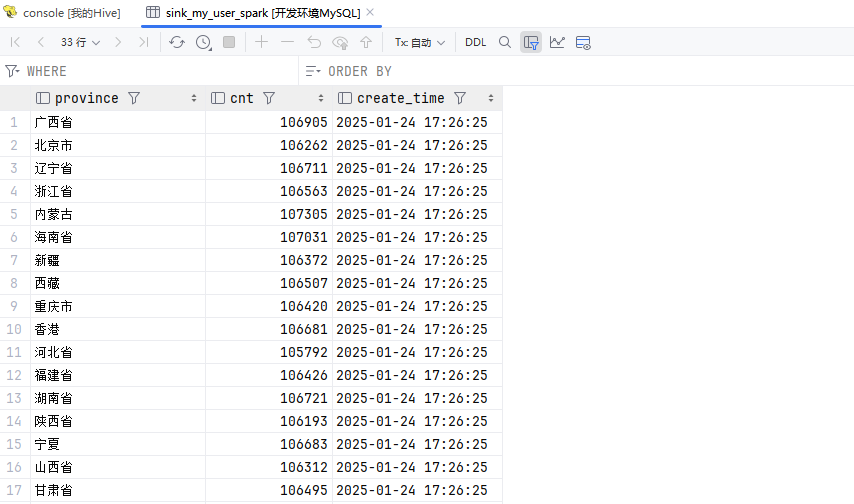
输出数据到外部存储
在 Spark 中,Dataset.write() 是用于将数据从 Dataset 保存到外部存储的接口。
MySQL
添加依赖
<properties>
<mysql.version>8.0.33</mysql.version>
</properties>
<dependencies>
<!-- MySQL Connector/J: MySQL数据库驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>编辑代码
package local.ateng.java.spark.sql.write;
import cn.hutool.core.util.StrUtil;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* 将查询的数据输出到MySQL
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class MySQL {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到MySQL");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
Dataset<Row> ds = spark.sql(sql);
// 设置MySQL连接属性
String jdbcUrl = "jdbc:mysql://192.168.1.10:35725/kongyu";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "Admin@123");
// 将数据写入MySQL
ds.write()
.mode(SaveMode.Overwrite) // 可根据需求选择保存模式,这里选择覆盖已存在的表
.jdbc(jdbcUrl, "sink_my_user_spark", connectionProperties);
// 停止SparkSession,释放资源
spark.stop();
}
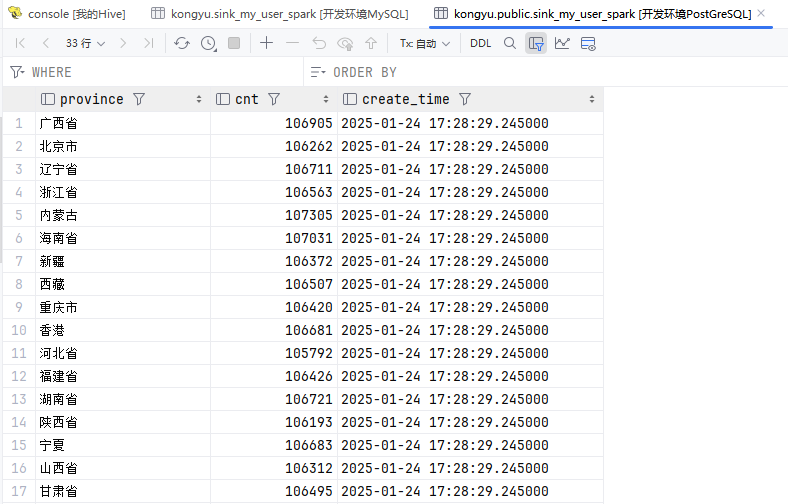
}
PostgreSQL
添加依赖
<properties>
<postgresql.version>42.7.1</postgresql.version>
</properties>
<dependencies>
<!--连接Postgresql数据库-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgresql.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>编辑代码
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* 将查询的数据输出到PostgreSQL
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class PostgreSQL {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到PostgreSQL");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
Dataset<Row> ds = spark.sql(sql);
// 设置PostgreSQL连接属性
String jdbcUrl = "jdbc:postgresql://192.168.1.10:32297/kongyu?currentSchema=public";
Properties connectionProperties = new Properties();
connectionProperties.put("user", "postgres");
connectionProperties.put("password", "Lingo@local_postgresql_5432");
// 将数据写入MySQL
ds.write()
.mode(SaveMode.Overwrite) // 可根据需求选择保存模式,这里选择覆盖已存在的表
.jdbc(jdbcUrl, "sink_my_user_spark", connectionProperties);
// 停止SparkSession,释放资源
spark.stop();
}
}
Kafka
添加依赖
<!-- Spark写入Kafka依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
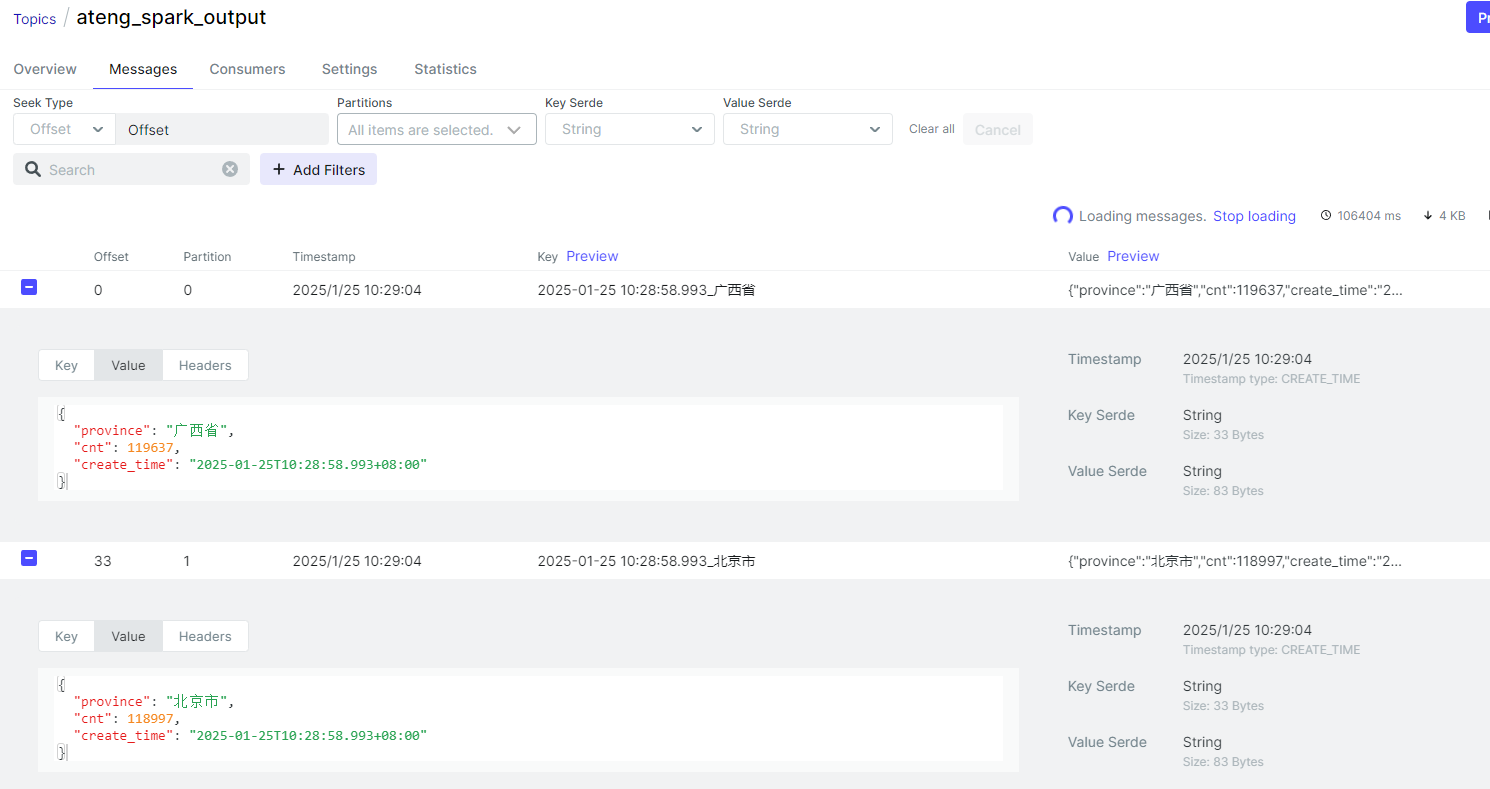
</dependency>将查询结果的每一行数据分别推送到Kafka中
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* 将查询的数据输出到Kafka
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class Kafka {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到KafkaL");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
Dataset<Row> ds = spark.sql(sql);
// 将 DataFrame 转换为 JSON 格式(Kafka 需要值是二进制 JSON)
Dataset<Row> messageDF = ds.selectExpr(
"concat(CAST(CURRENT_TIMESTAMP AS STRING), '_', province) AS key",
"to_json(struct(*)) AS value"
);
// 配置 Kafka 参数
String kafkaServers = "192.168.1.10:9094"; // Kafka 集群地址
String topic = "ateng_spark_output"; // Kafka 目标 Topic
// 将结果写入 Kafka
messageDF
.write()
.format("kafka") // 使用 Kafka 数据源格式
.option("kafka.bootstrap.servers", kafkaServers) // Kafka 服务器地址
.option("topic", topic) // Kafka 目标 Topic
.save(); // 写入 Kafka
// 停止SparkSession,释放资源
spark.stop();
}
}
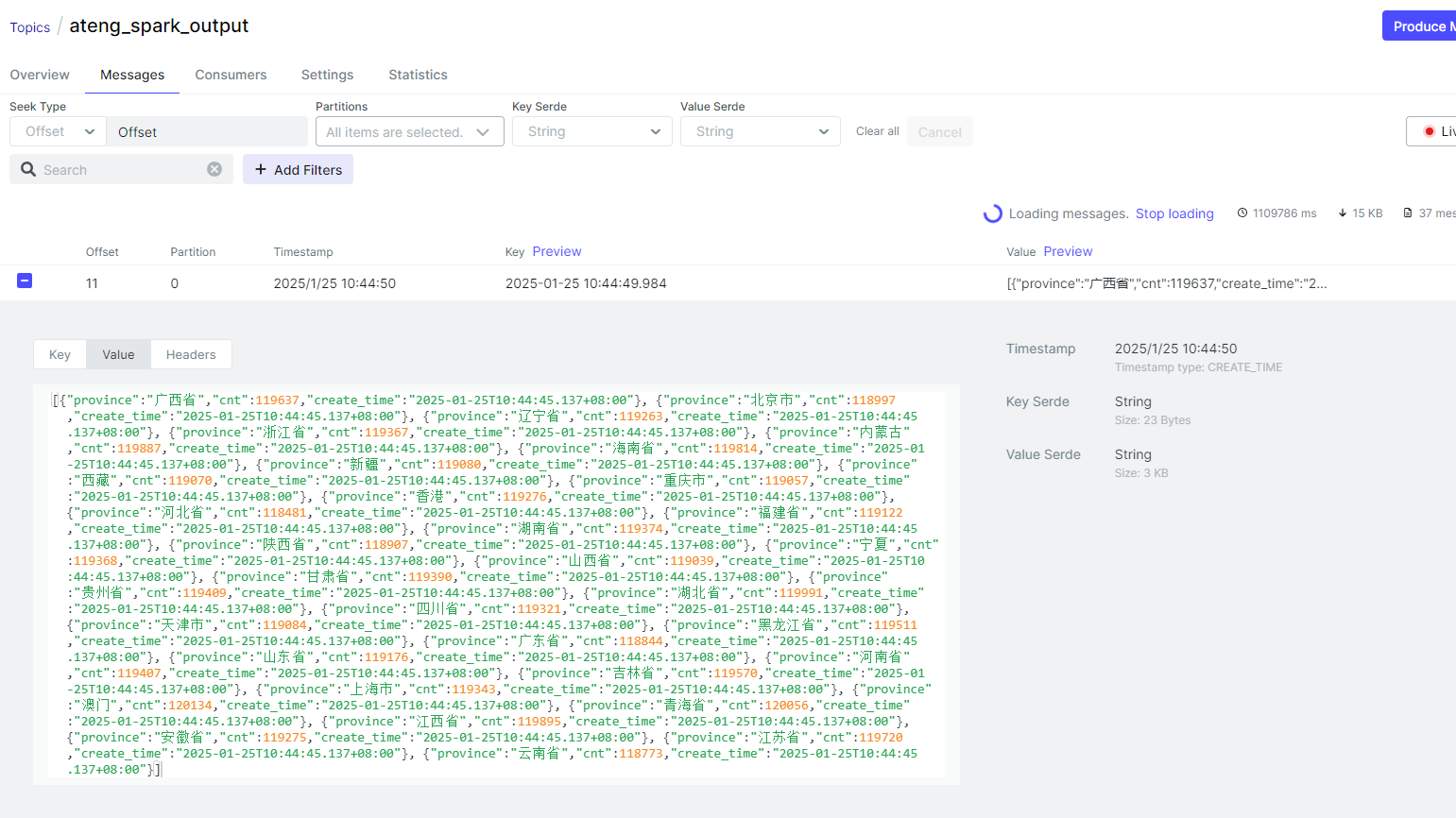
将查询结果的所有数据转换成一条数据推送到Kafka中
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 将查询的数据输出到Kafka,只输出一条数据JSONArray
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class KafkaOneMsg {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到KafkaL");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
Dataset<Row> ds = spark.sql(sql);
// 将整个数据集转换为一个单一的 JSON 字符串
String jsonMessage = ds.toJSON().collectAsList().toString(); // 将数据转换为 JSON 格式并转换成一个 List
// 将整个数据集作为单一消息(整个数据拼接为一个大 JSON 字符串)
Dataset<Row> messageDF = spark.createDataset(
java.util.Collections.singletonList(jsonMessage),
org.apache.spark.sql.Encoders.STRING()
).toDF("value")
.selectExpr(
"value", // 消息数据列
"CAST(CURRENT_TIMESTAMP AS STRING) AS key" // 直接定义 key 列为当前时间戳
);
messageDF.show();
// 配置 Kafka 参数
String kafkaServers = "192.168.1.10:9094"; // Kafka 集群地址
String topic = "ateng_spark_output"; // Kafka 目标 Topic
// 将结果写入 Kafka
messageDF
.write()
.format("kafka") // 使用 Kafka 数据源格式
.option("kafka.bootstrap.servers", kafkaServers) // Kafka 服务器地址
.option("topic", topic) // Kafka 目标 Topic
.save(); // 写入 Kafka
// 停止SparkSession,释放资源
spark.stop();
}
}
Doris
参考:官方文档
添加依赖
<dependencies>
<!--Spark Doris Connector-->
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>spark-doris-connector-spark-3.5</artifactId>
<version>24.0.0</version>
</dependency>
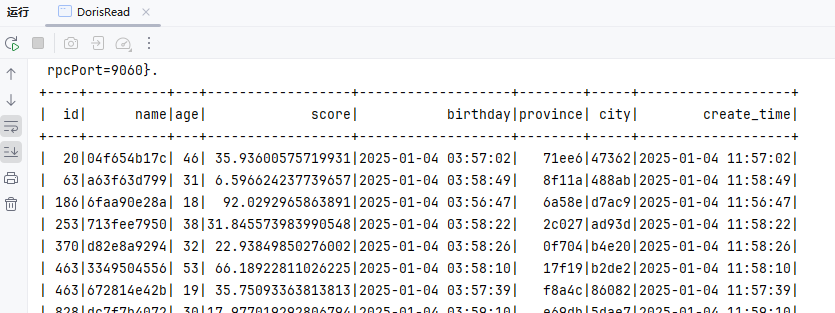
</dependencies>读取数据
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;
/**
* 读取Doris的数据
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class DorisRead {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("读取Doris的数据");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 创建Doris视图
spark.sql("CREATE TEMPORARY VIEW spark_doris\n" +
" USING doris\n" +
" OPTIONS(\n" +
" \"table.identifier\"=\"kongyu.my_user_doris\",\n" +
" \"fenodes\"=\"192.168.1.12:9040\",\n" +
" \"user\"=\"admin\",\n" +
" \"password\"=\"Admin@123\"\n" +
");");
// 查询数据
spark.sql("select * from spark_doris limit 100").show();
// 停止SparkSession,释放资源
spark.stop();
}
}
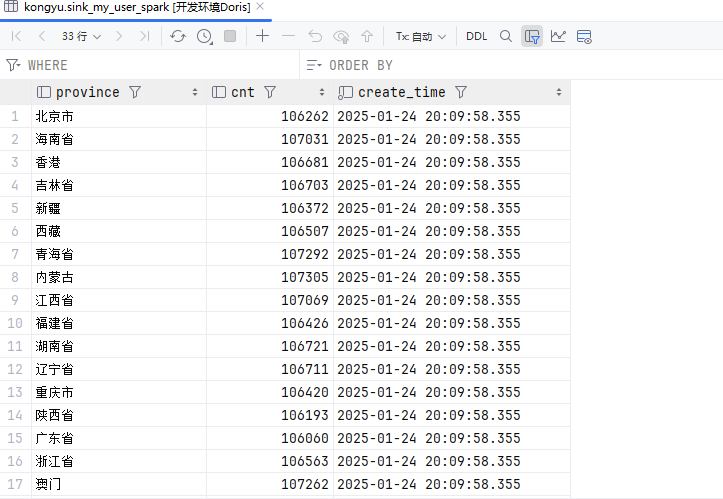
写入数据
Doris创建表
drop table if exists kongyu.sink_my_user_spark;
create table if not exists kongyu.sink_my_user_spark
(
province varchar(50) comment '所在省份',
cnt bigint comment '数量',
create_time datetime(3) not null default current_timestamp(3) comment '数据创建时间'
)
DUPLICATE KEY(province)
DISTRIBUTED BY HASH(province) BUCKETS AUTO
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
show create table kongyu.sink_my_user_spark;使用DataFrame
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
/**
* 将查询的数据输出到Doris
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class DorisWriteDataFrame {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到Doris");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
Dataset<Row> ds = spark.sql(sql);
// 写入数据到Doris
ds.write().format("doris")
.option("doris.table.identifier", "kongyu.sink_my_user_spark")
.option("doris.fenodes", "192.168.1.12:9040")
.option("user", "admin")
.option("password", "Admin@123")
.mode(SaveMode.Append)
.save();
// 停止SparkSession,释放资源
spark.stop();
}
}
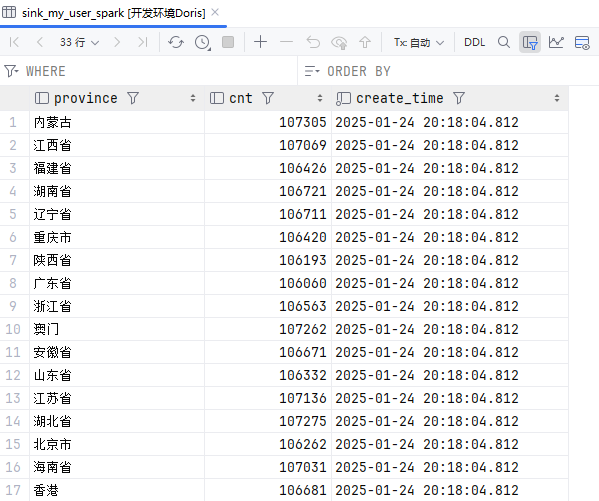
使用SparkSQL
SQL
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="kongyu.sink_my_user_spark",
"fenodes"="192.168.1.12:9040",
"user"="admin",
"password"="Admin@123"
);代码
package local.ateng.java.spark.sql.write;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
/**
* 将查询的数据输出到Doris
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class DorisWrite {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到Doris");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 创建Doris视图
spark.sql("CREATE TEMPORARY VIEW spark_doris\n" +
" USING doris\n" +
" OPTIONS(\n" +
" \"table.identifier\"=\"kongyu.sink_my_user_spark\",\n" +
" \"fenodes\"=\"192.168.1.12:9040\",\n" +
" \"user\"=\"admin\",\n" +
" \"password\"=\"Admin@123\"\n" +
");");
// 写入数据到Doris,insert into select | insert overwrite select
String sql = "INSERT INTO spark_doris SELECT \n" +
" province, \n" +
" COUNT(id) AS cnt, \n" +
" CURRENT_TIMESTAMP() AS create_time \n" +
"FROM \n" +
" my_user\n" +
"GROUP BY \n" +
" province;\n";
spark.sql(sql);
// 停止SparkSession,释放资源
spark.stop();
}
}
HDFS
写入JSON格式
package local.ateng.java.spark.sql.write;
import cn.hutool.core.util.StrUtil;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
/**
* 写入HDFS为JSON文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class HDFS2Json {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("写入HDFS为JSON文件");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT * FROM my_user WHERE province = '{}'";
Dataset<Row> ds = spark.sql(StrUtil.format(sql, "重庆市"));
// 将结果写入到 HDFS 的 JSON 文件
ds.write()
.mode(SaveMode.Overwrite)
.json("hdfs://server01:8020/data/spark/output");
// 停止SparkSession,释放资源
spark.stop();
}
}
写入CSV格式
package local.ateng.java.spark.sql.write;
import cn.hutool.core.util.StrUtil;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
/**
* 写入HDFS为CSV文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class HDFS2Csv {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("写入HDFS为CSV文件");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT * FROM my_user WHERE province = '{}'";
Dataset<Row> ds = spark.sql(StrUtil.format(sql, "重庆市"));
// 将结果写入到 HDFS 的 CSV 文件
ds.write()
.mode(SaveMode.Overwrite)
.option("header", "true") // 启用表头
.option("delimiter", ",") // 设置分隔符
.option("quote", "\"") // 指定引用符
.option("escape", "\\") // 指定转义符
.csv("hdfs://server01:8020/data/spark/output");
// 停止SparkSession,释放资源
spark.stop();
}
}
写入Parquet格式
package local.ateng.java.spark.sql.write;
import cn.hutool.core.util.StrUtil;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
/**
* 写入HDFS为Parquet文件
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class HDFS2Parquet {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("写入HDFS为Parquet文件");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 执行SQL查询
String sql = "SELECT * FROM my_user WHERE province = '{}'";
Dataset<Row> ds = spark.sql(StrUtil.format(sql, "重庆市"));
// 将结果写入到 HDFS 的 Parquet 文件
ds.write()
.mode(SaveMode.Overwrite)
.parquet("hdfs://server01:8020/data/spark/output");
// 停止SparkSession,释放资源
spark.stop();
}
}
Catalog
在 Spark SQL 中,Catalog 是用于管理数据库、表、视图、函数和其他元数据的接口。通过 Catalog,可以方便地操作元数据,也可以查看和管理当前 Spark 会话中的临时表、全局视图以及用户定义的函数。
Doris
参考:官方文档
package local.ateng.java.spark.catalog;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;
/**
* Spark Doris Catalog
* https://doris.apache.org/zh-CN/docs/ecosystem/spark-doris-connector#spark-doris-catalog
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class Doris {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("将查询的数据输出到Doris");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置 Doris Catalog
conf.set("spark.sql.catalog.doris_catalog", "org.apache.doris.spark.catalog.DorisTableCatalog");
conf.set("spark.sql.catalog.doris_catalog.doris.fenodes", "192.168.1.12:9040");
conf.set("spark.sql.catalog.doris_catalog.doris.query.port", "9030");
conf.set("spark.sql.catalog.doris_catalog.doris.user", "admin");
conf.set("spark.sql.catalog.doris_catalog.doris.password", "Admin@123");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 设置当前Catalog
spark.catalog().setCurrentCatalog("doris_catalog");
// 查询 databases
spark.sql("show databases").show();
// 查询数据
spark.sql("select * from kongyu.my_user_doris limit 10").show();
// 停止SparkSession,释放资源
spark.stop();
}
}Iceberg
参考:官方文档
配置MinIO环境变量
AWS_ACCESS_KEY_ID=admin
AWS_SECRET_ACCESS_KEY=Lingo@local_minio_9000
AWS_REGION=us-east-1添加依赖
<!--Spark 集成 Iceberg 依赖-->
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-spark-runtime-3.5_2.12</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-aws-bundle</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>编辑代码
package local.ateng.java.spark.catalog;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;
/**
* Spark 集成 Iceberg
* https://iceberg.apache.org/docs/nightly/spark-getting-started/
*
* @author 孔余
* @email 2385569970@qq.com
* @since 2025-01-24
*/
public class Iceberg {
public static void main(String[] args) {
// 创建Spark配置
SparkConf conf = new SparkConf();
// 设置应用程序的名称
conf.setAppName("Spark 集成 Iceberg");
// 指定hive仓库中的默认位置
conf.set("spark.sql.warehouse.dir", "hdfs://server01:8020/hive/warehouse");
// 设置 Iceberg Catalog
conf.set("spark.sql.catalog.iceberg_catalog", "org.apache.iceberg.spark.SparkCatalog");
conf.set("spark.sql.catalog.iceberg_catalog.warehouse", "s3://iceberg-bucket/warehouse");
conf.set("spark.sql.catalog.iceberg_catalog.s3.endpoint", "http://192.168.1.13:9000");
conf.set("spark.sql.catalog.iceberg_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO");
conf.set("spark.sql.catalog.iceberg_catalog.catalog-impl", "org.apache.iceberg.jdbc.JdbcCatalog");
conf.set("spark.sql.catalog.iceberg_catalog.uri", "jdbc:postgresql://192.168.1.10:32297/iceberg");
conf.set("spark.sql.catalog.iceberg_catalog.jdbc.user", "postgres");
conf.set("spark.sql.catalog.iceberg_catalog.jdbc.password", "Lingo@local_postgresql_5432");
conf.set("spark.sql.catalog.iceberg_catalog.jdbc.schema-version", "V1");
// 设置运行环境
String masterValue = conf.get("spark.master", "local[*]");
conf.setMaster(masterValue);
// 创建一个SparkSession对象,同时配置SparkConf,并启用Hive支持
SparkSession spark = SparkSession
.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate();
// 设置当前Catalog
spark.catalog().setCurrentCatalog("iceberg_catalog");
// 创建一个名为 "spark" 的数据库,如果不存在则创建
spark.sql("CREATE DATABASE IF NOT EXISTS spark;");
// 显示当前 SparkSession 中的所有数据库
spark.sql("show databases").show();
// 切换到 "spark" 数据库
spark.sql("use spark");
// 在 "spark" 数据库中创建一张名为 "my_user" 的表,如果表不存在
spark.sql("CREATE TABLE IF NOT EXISTS my_user (\n" +
" id BIGINT NOT NULL,\n" +
" name STRING,\n" +
" age INT,\n" +
" score DOUBLE,\n" +
" birthday TIMESTAMP,\n" +
" province STRING,\n" +
" city STRING,\n" +
" create_time TIMESTAMP\n" +
") USING iceberg;");
// 显示当前数据库中的所有表
spark.sql("show tables").show();
// 向 "my_user" 表中插入三条记录,分别表示三位用户的信息
spark.sql("INSERT INTO my_user VALUES \n" +
"(1, 'Alice', 30, 85.5, TIMESTAMP '1993-01-15 10:00:00', 'Beijing', 'Beijing', TIMESTAMP '2023-07-01 10:00:00'),\n" +
"(2, 'Bob', 25, 90.0, TIMESTAMP '1998-06-20 14:30:00', 'Shanghai', 'Shanghai', TIMESTAMP '2023-07-01 11:00:00'),\n" +
"(3, 'Carol', 28, 95.0, TIMESTAMP '1995-12-05 09:45:00', 'Guangdong', 'Guangzhou', TIMESTAMP '2023-07-02 09:00:00');\n");
// 查询 "my_user" 表中的所有数据并打印
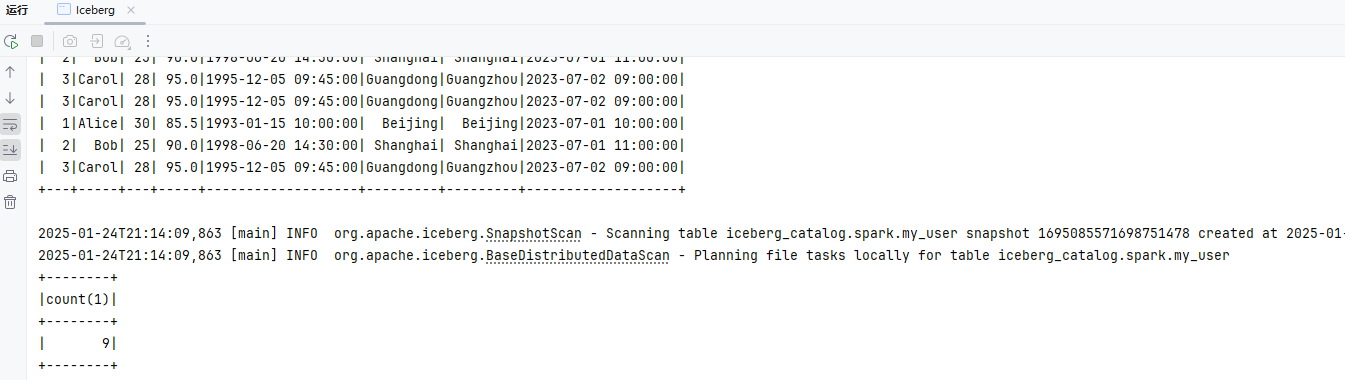
spark.sql("SELECT * FROM my_user;").show();
// 查询 "my_user" 表中记录的总数并打印
spark.sql("SELECT count(*) FROM my_user;").show();
// 停止SparkSession,释放资源
spark.stop();
}
}